
AI Glossary: Understanding Commonly (Mis)used AI Terms
There is plenty to be excited about when it comes to artificial intelligence and machine learning. More businesses across the globe are recognizing the upside of investing in AI/ML to improve their operations. Google, Microsoft, and Amazon each have their own machine learning platform and have worked with enterprises to implement artificial intelligence. If you are familiar with spam detection by your email provider, that is machine learning. So is the ‘facial recognition’ that allows Facebook to tag and sort images of particular people.
The technology is going to affect every business, even those who don’t normally invest in technology. Artificial intelligence is going to revolutionize the construction industry by improving project management workflows, streamlining the design phase, optimizing drone land surveying, improving employee safety, and gathering crucial on-site data. As machine learning becomes more sophisticated, the use cases will continue to multiply and dramatically affect every industry.
To demonstrate machine learning in action, we decided to conduct a simple experiment showcasing how image recognition works on each machine learning platform.
In our experiment, we wanted to compare how each machine learning platform handles image recognition processing and how quality of data affects the results. We chose three major platforms:
The functionality of our API service end-points follows this order:
To gain access to each platform’s SDK and libraries, we needed to create accounts, gain an authentication key, and utilize the .NET Core API service. We then needed to get the client libraries into the Visual Studio project. These are the packages we included for Amazon, Google, and Microsoft respectively:



In the next step, we created three async methods in our .NET core controller using the file as a parameter and returning a JSON string as the result.
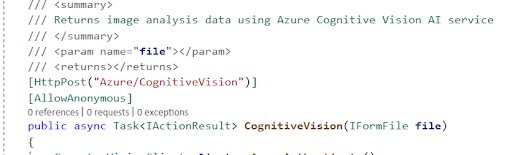


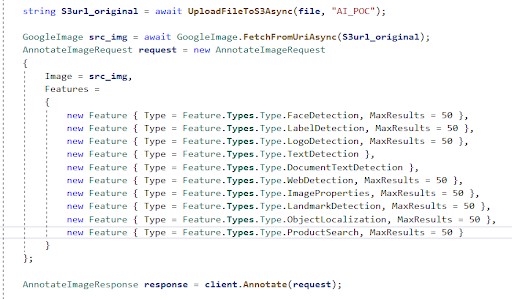
In each SDK, we are allowed to analyze the file by providing its URL. In our example, we uploaded the image file to S3 and passed the S3 URL to each client for analysis. For instance, the Google Cloud Vision method looks something like this…
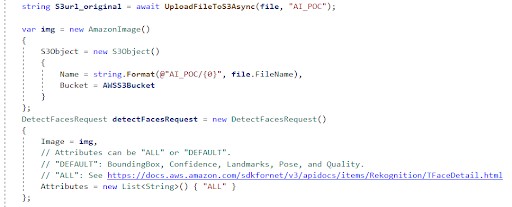
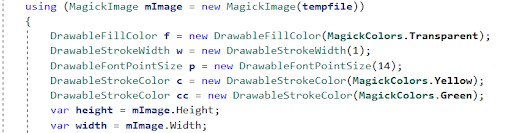
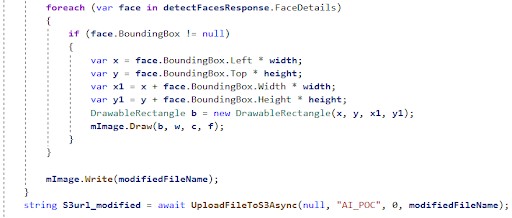
When altering the image, we decided to use the ImageMagick library. ImageMagick provides a variety of options for image manipulation. In the code snippet below, we demonstrate how Amazon Rekognition AI and ImageMagick library can be used to detect faces, draw rectangles based on returned boundaries for each detected instance, save the altered image to S3, and return the result.
![]()

We built our API using Swagger Tool and were able to see the results from each AI service without creating separate client UIs.
That takes care of the server side!
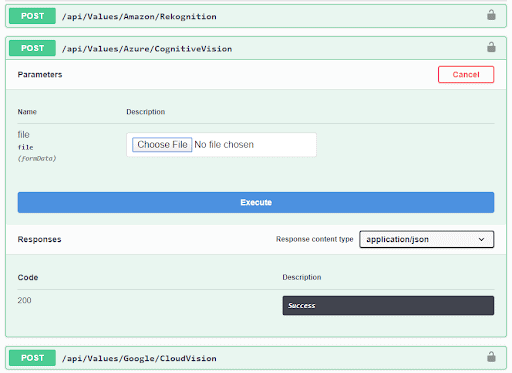
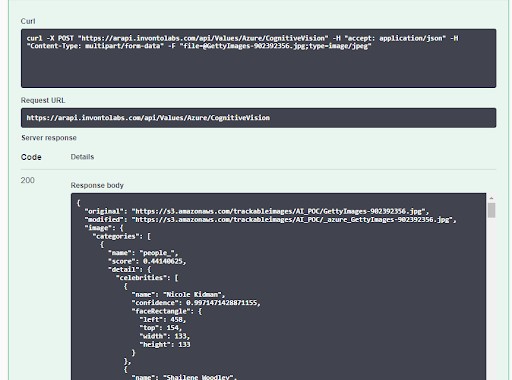
The server-side took care of most of the work for this experiment. Now, we need a simple web-based UI that allows users to interact with our machine learning experiment. Our front-end utilized Angular 7, and allowed users to select an image from their local PC and run an image analysis by calling one of our AI API end-points. The results would return with the original and altered image side-by-side.
Because we have three different APIs, we grouped them in tabs so that users could easily run an image analysis and see the results from each machine learning platform. A few extra features we included were showing more visually appealing responses (the image’s dominant colors) and adding links to IMDB if a celebrity is detected.
You can use the completed experiment here: https://ai.invontolabs.com/
Now that the application is built, we need to run images through the system. We decided to use images of famous people to compare how each machine learning service detects and recognizes faces. Below you can see the results of an image featuring some ‘moderately’ famous people (please read the sarcasm).

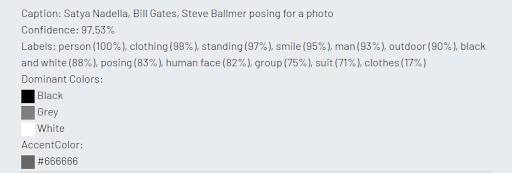

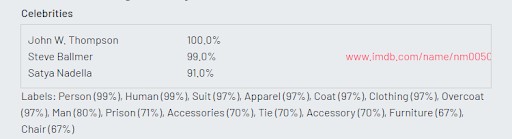


All three machine learning platforms detected the faces accurately. However, we noticed that Microsoft and Amazon were able to recognize and name three out of four celebrities. Microsoft did not recognize Microsoft chairman, John W. Thompson. Amazon hilariously ignored Bill Gates (perhaps intentionally?). Google recognized all four Microsoft executives.



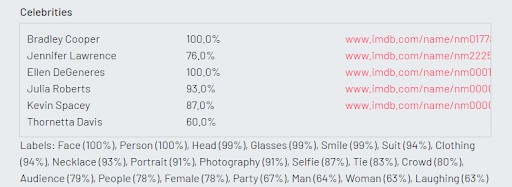

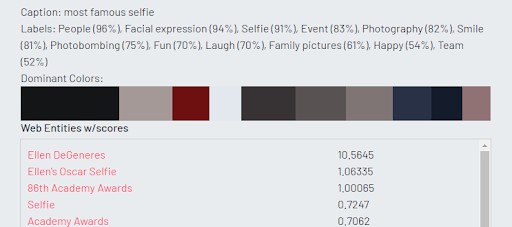
Our next photo might look familiar. It is the famous Oscar’s selfie from the 2014 ceremony. Microsoft could not detect all the faces, but was able to recognize three Hollywood celebrities. Google did not accurately recognize each celebrity, but rather described keywords related to the image. Amazon’s results were the most accurate. It was able to recognize six celebrities and also offered links to the IMDB profiles for each celebrity (Amazon owns IMDB and so has access to the data).
In our next image, we decided to analyze famous landmarks and compare the results. Our first landmark is from the collection of our talented developer, Anatoly Volkovich. The scene shows a famous sculpture in the front of a museum in Bilbao, Spain (extra points if you know which museum this is before scrolling).




After reviewing the results, it seems that Google is best suited to detect landmarks. It not only recognized the landmark, but also included GPS coordinates and a link to more information. Microsoft was also able to correctly identify the Guggenheim Museum Bilbao. Amazon was able to detect that the image contained an architectural structure, but could not name the location or provide more information.
Some members of the development team enjoy lunch at the Shake Shack by Invonto’s Bridgewater New Jersey headquarters. Let’s see if these machine learning platforms will recognize the brand using a simple logo.
![]()
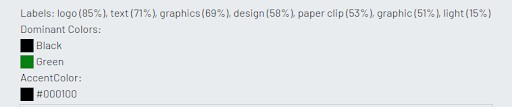
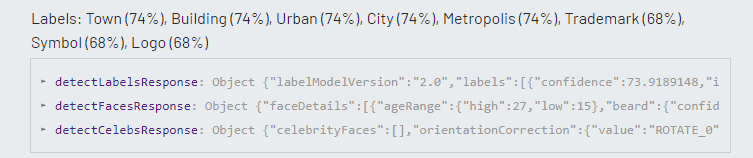
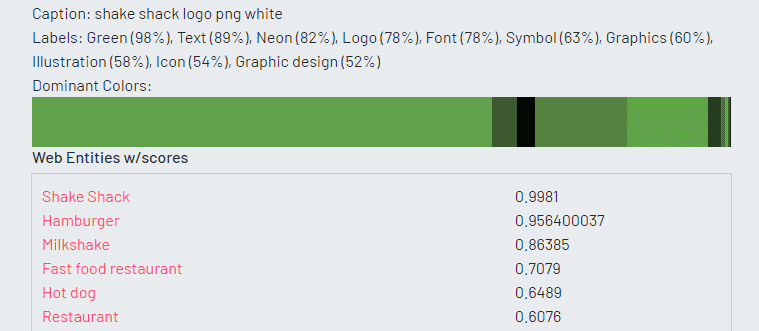
Microsoft recognized the image as a logo, but could not identify the brand as Shake Shack. Amazon returned similar results, but incorrectly labeled the image with terms like ‘town’ and ‘building’ with a high level of confidence. Google was the only machine learning platform that was able to accurately identify the image as the Shake Shack logo.
In our final exercise, we test whether each platform can recognize text accurately.

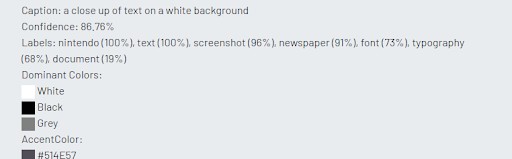
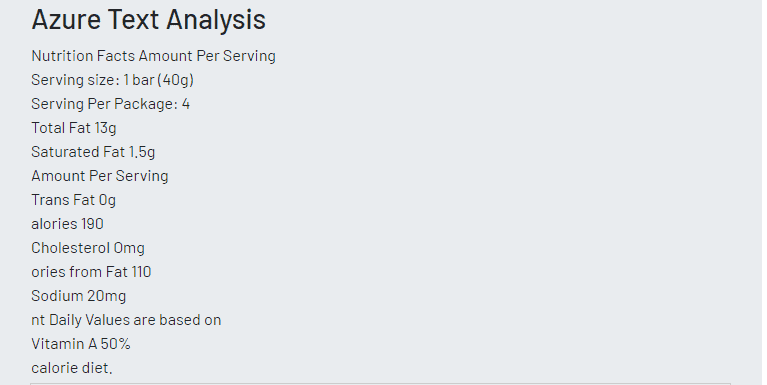
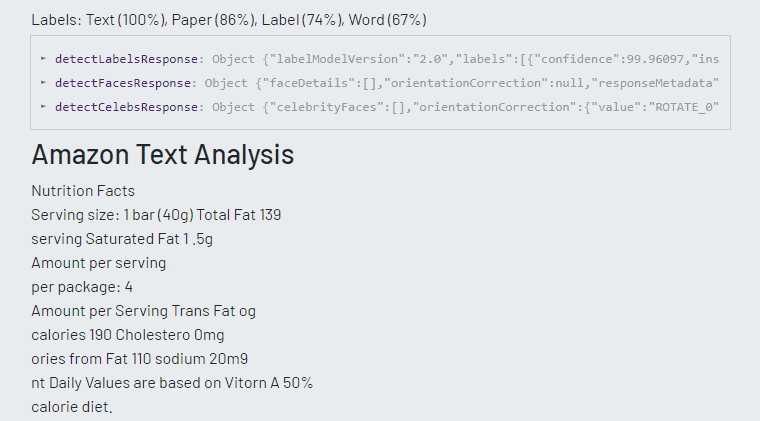
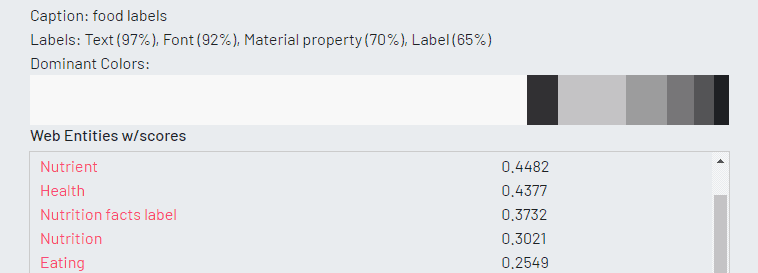
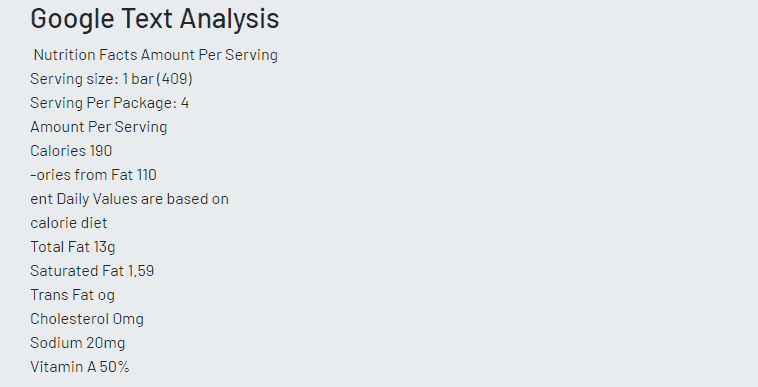
All three platforms did a good job of translating the food label image into text. Both Microsoft and Google excelled in detecting words within the image that are out of focus. Google was the only one that could categorize the image as ‘food label’.
After experimenting with several images, we can understand the strengths and weaknesses of each platform. Amazon handles facial recognition excellently. Google could identify landmarks, brand marks, and text. Microsoft seemed to perform the least consistently, being unable to identify more detailed image information. Quality of data is critical in the success of a machine learning application and for appropriate data analysis. A lack of data or garbage data can skew the results, often leading to mis-information. Depending on the machine learning application you want to build, you may want to weigh the benefits of choosing a platform based on the areas in which they perform best. You should also ensure that you have access to data necessary for a proper functioning of your application.


